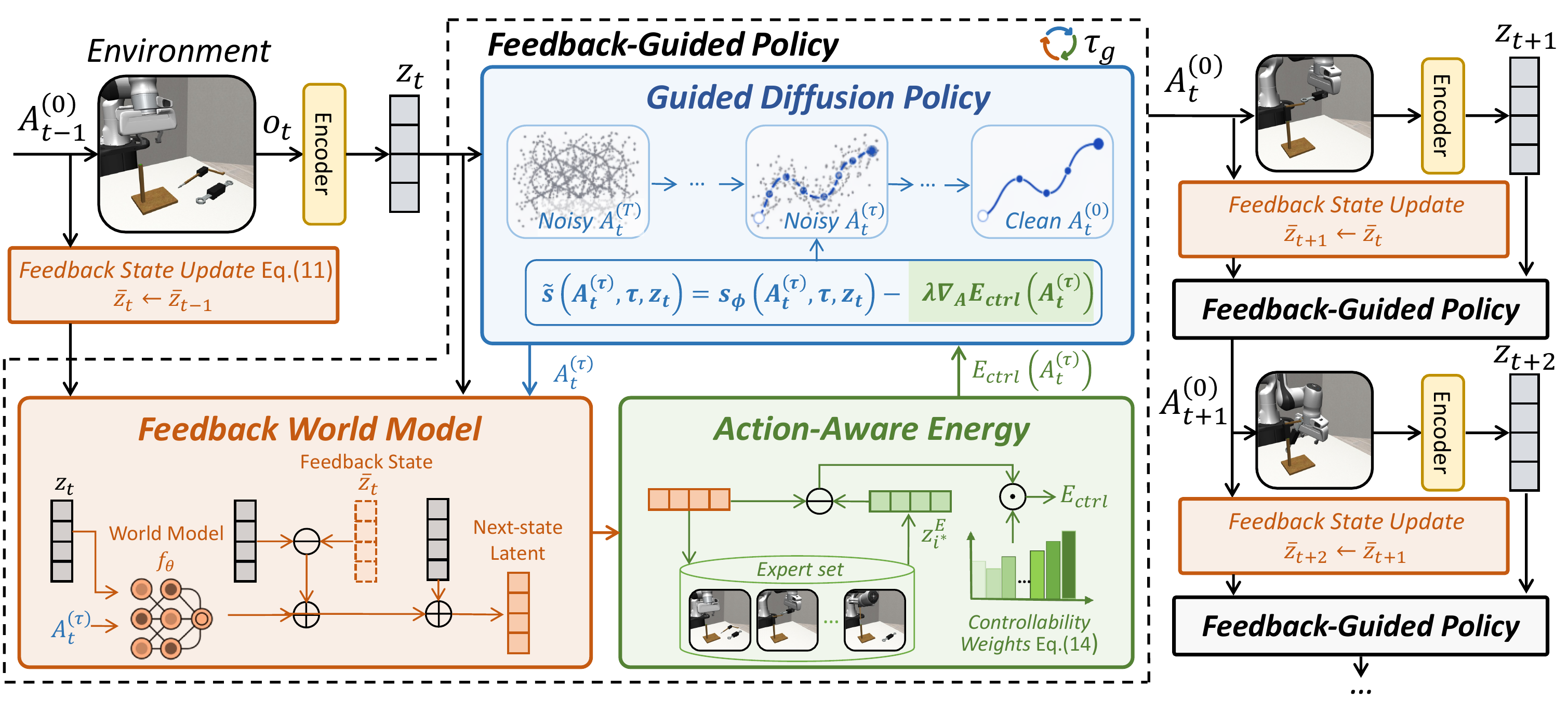
World models predict robot futures and steer policies—until the robot drifts out of distribution and the predictions go stale.
We turn each executed action into a free correction signal: the gap between the model's prediction and the robot's actual next observation is fed back online to keep the world model honest—with no extra training data, no parameter updates. Combined with action-aware guidance that focuses on the dimensions a robot can actually move, this closed-loop view forms our feedback world model.
Real-World Demos
Three tasks on a physical arm, two policies side by side: Baseline diffusion policy (left) versus Ours with the feedback world model and action-aware guidance (right). The robot starts each rollout from an out-of-distribution pose; clips loop at 16× real time, shown from a top-down and a side camera.
Peach Pick-and-Place
Drawer-Open
Drawer-Open — Variation
Closing the Loop at Inference Time
Most world-model guidance methods treat the model as a static open-loop predictor at deployment. New observations seed the next prediction but never correct the model's own state, so prediction error compounds — the longer the horizon and the further from the training distribution, the worse it gets.
Our feedback world model carries a small additional state that is refreshed after every environment step. The gap between the predicted and the actually observed transition becomes a corrective signal for subsequent predictions, with no extra training data and no parameter updates. From a control perspective the update reads as a latent-space observer; under a linear feedback formulation it admits convergence guarantees. Algorithm 1 below distils the full recipe: a one-time offline pass for action-aware weights, then a single online loop that wraps standard denoising with feedback correction.
Insight. Deployment is already producing a free supervision signal: every executed action surfaces the gap between what was predicted and what actually happened. We close that loop online, turning a fixed open-loop predictor into an observer that self-corrects.
Action-Aware Guidance
Better predictions are only useful if guidance can act on them. Action-aware guidance weights latent dimensions by how strongly each one responds to the candidate action — end-effector motion, object pose, contact moments — and downweights what the robot cannot move: background, lighting, texture.
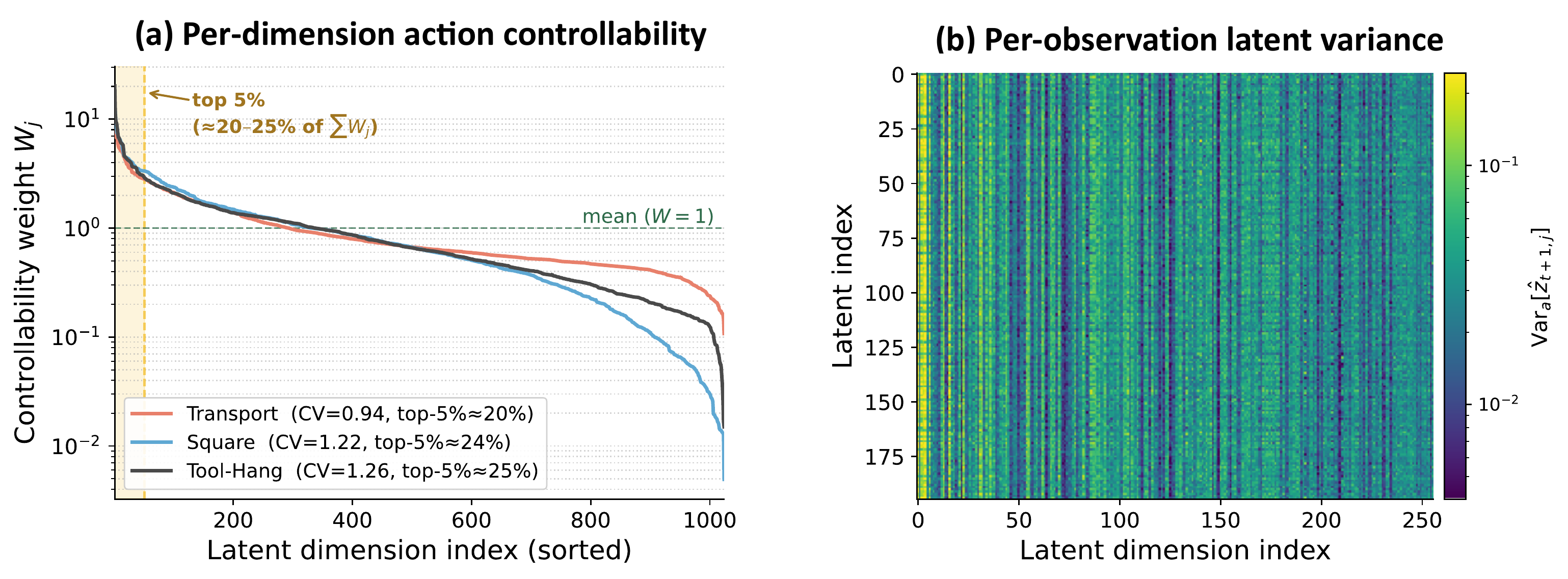
Per-dimension action controllability is estimated once, offline, from expert rollouts. At inference, this weighting concentrates the gradient on directions the policy can actually influence, suppressing noise from action-irrelevant variation.
Quantitative Results
We benchmark across four LIBERO-10 tasks from LIBERO-Plus, three representative Robomimic tasks, and two real-world manipulation tasks. Every task is perturbed in its initial robot pose to push the policy into out-of-distribution territory. Feedback correction cuts world-model prediction error by up to 76.4%, and the resulting policy lifts the average OOD success rate by 30%.

Latent prediction MSE under OOD perturbations. Base WM is the open-loop predictor; feedback correction lowers the error on every task.

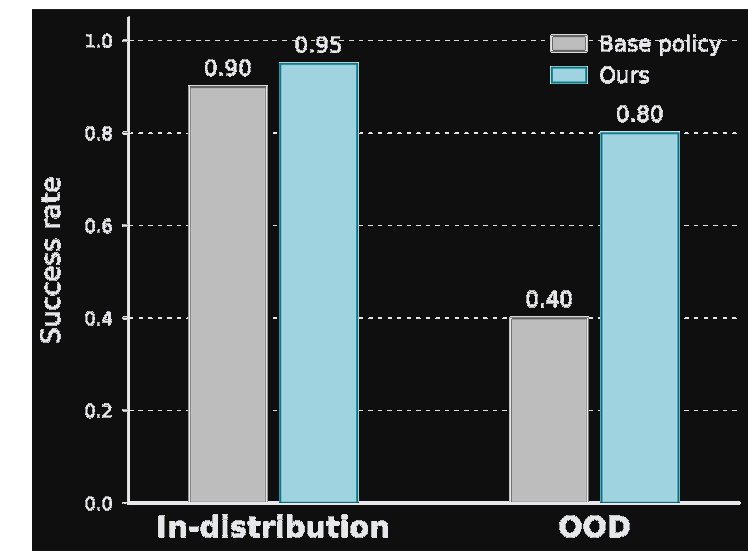
Real-world OOD success rate. Combining feedback correction with action-aware guidance yields the largest gains over the base diffusion policy.
Qualitative Results
Simulated tasks. Four LIBERO-Plus settings drawn from LIBERO-10, plus three Robomimic tasks — each evaluated with the robot's initial pose perturbed out of the training distribution.

Real-world deployment. Peach pick-and-place and drawer-open on a physical arm. The baseline drifts as soon as the initial pose moves; our closed-loop policy stays on task and the OOD success rate roughly doubles.

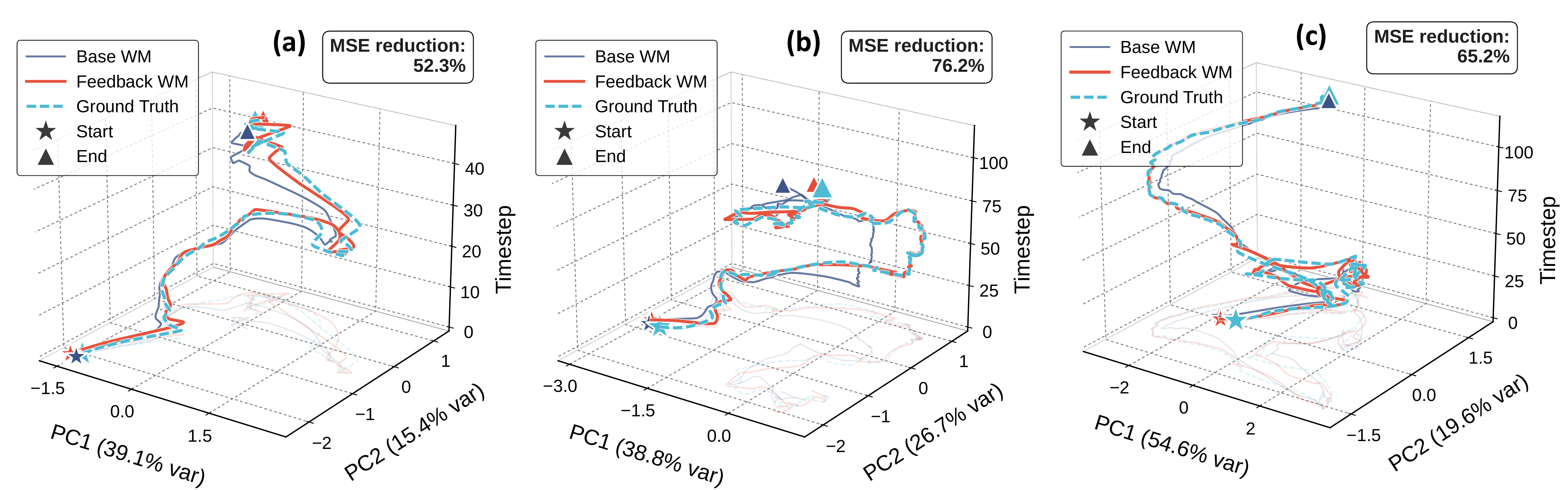
Latent-space trajectories. Predicted and observed states are projected into the world-model latent space at every step. Without correction, the predicted trajectory peels away from the expert manifold; with feedback, it is pulled back in over time.
Simulation OOD Scenes
To probe robustness under controlled distribution shift, we re-initialise each Robomimic task by sampling small joint-angle offsets on the robot arms; everything else — object placement, lighting, viewpoint — is held fixed. Each row shows the in-distribution start (left) next to three increasingly perturbed OOD starts, from two camera angles.
Square








Top row: agentview camera · Bottom row: front-view camera.
ToolHang








Top row: side view · Bottom row: front view.
Transport (dual-arm)
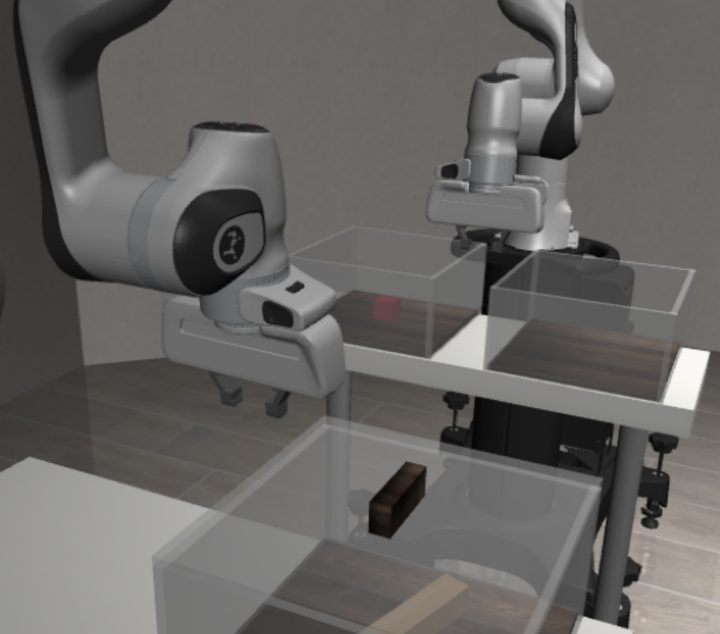





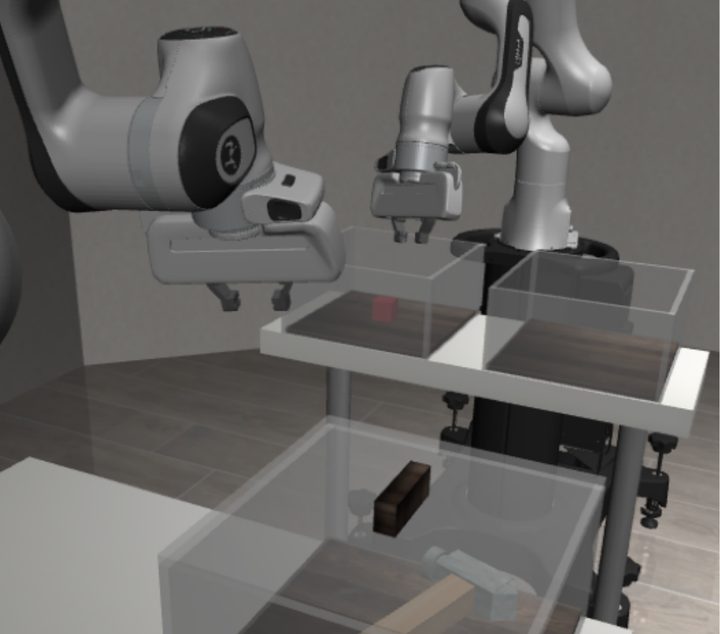

Top row: shoulder camera 0 · Bottom row: robot-0 wrist camera. Arm-joint perturbations are sampled independently for the two arms.
BibTeX
@misc{an2026feedback,
title = {Feedback World Model Enables Precise Guidance of Diffusion Policy},
author = {An, Tuo and Jia, Jindou and Li, Gen and Li, Jingliang and
Zhou, Chuhao and Liu, Pengfei and Lyu, Bofan and Bai, Jiaqi and
Guo, Xinying and Li, Geng and Yang, Jianfei},
year = {2026},
eprint = {2605.15705},
archivePrefix = {arXiv},
primaryClass = {cs.RO}
}